When we integrate our climate models we don't run the whole period in one go but rather run in smaller chunks of e.g. one month. This makes sure that we can fit the job into a slurm allocation and that in case of crashes, we can recover by starting again from the beginning of the chunk.
However, this is not trivial to do with my preferred workflow manager, snakemake, because it operates in the space of files and assumes that each rule is defined in terms of data, its input and output.
Here I describe a way to do it.
Recursive approach
My first natural approach was to write this as a basic recursion. We need a rule
for the output of a particular date that then uses a function to determine the
date of one month before that. Then we need a base_case for the first date:
1 from datetime import datetime, timedelta
2
3 rule all:
4 input:
5 "2021-01-01.txt"
6
7 def previous_month_input(wildcards):
8 current_date = datetime.strptime(f"{wildcards.year}-{wildcards.month}-01", "%Y-%m-%d")
9 previous_date = current_date - timedelta(days=1)
10 return f"{previous_date.year}-{previous_date.month:02d}-01.txt"
11
12 rule monthly_recursive:
13 input:
14 previous_month_input
15 output:
16 "{year}-{month}-01.txt"
17 shell:
18 "echo 'hello' > {output}"
19
20 rule base_case:
21 output: "2020-01-01.txt"
22 shell:
23 " echo 'initial' > {output}"
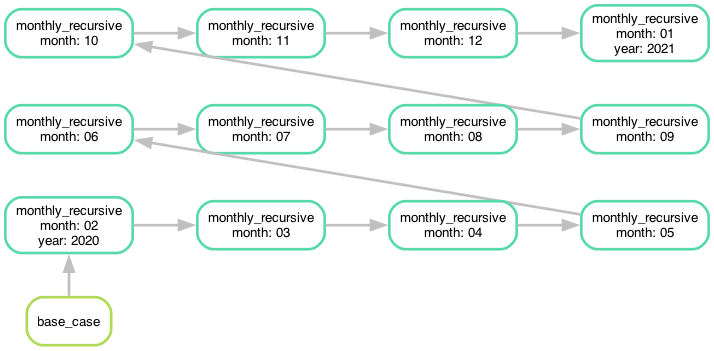
This works and is quite clean, but the problem here is that there is no tail call elimination (TCE) in python and therefore the stack growths quickly. So, if we try a longer period we will run into this error:
snakemake -c 1 2150-01-01.txt
Assuming unrestricted shared filesystem usage.
host: bkli04m065.local
Building DAG of jobs...
WorkflowError:
RecursionError: maximum recursion depth exceeded
If building the DAG exceeds the recursion limit, this is likely due to a cyclic dependency.E.g.
you might have a sequence of rules that can generate their own input.
Try to make the output files more specific. A common pattern is to have different
prefixes in the output files of different rules.
Problematic file pattern: 2109-10-01.txt
The problem appears after a bit more than 480 months. I am not exactly sure how
that fits with the default recursion limit in python of 1000. (This limit can
be increased with sys.setrecursionlimit(1500)).
A workaround would be to not directly ask for the latest date, but include a few
steps in between so that the recursion limit is never reached. However this seems
a little bit inconvienient.
Procedural approach
Another approach is to first generate a list of dates and then loop through that list and generate a new rule for each pair of consecutive dates:
1 from datetime import datetime, timedelta
2
3 def get_monthly_dates(start_year, end_year):
4 return [
5 datetime(year, month, 1)
6 for year in range(start_year, end_year + 1)
7 for month in range(1, 13)
8 ]
9
10
11 datelist = get_monthly_dates(2020, 2022)
12
13 def create_rule(date, previous_date):
14 rule:
15 name: f"month_{date}"
16 input: f"{previous_date}.txt"
17 output: f"{date}.txt"
18 shell:
19 "echo 'jojo' > {output}"
20
21 rule base_case:
22 output: "2020-01-01.txt"
23 shell:
24 " echo 'initial' > {output}"
25
26
27 # generate rules
28 for prev, curr in zip(datelist, datelist[1:]):
29 prev_str = prev.strftime("%Y-%m-%d")
30 curr_str = curr.strftime("%Y-%m-%d")
31 create_rule(curr_str, prev_str)
32
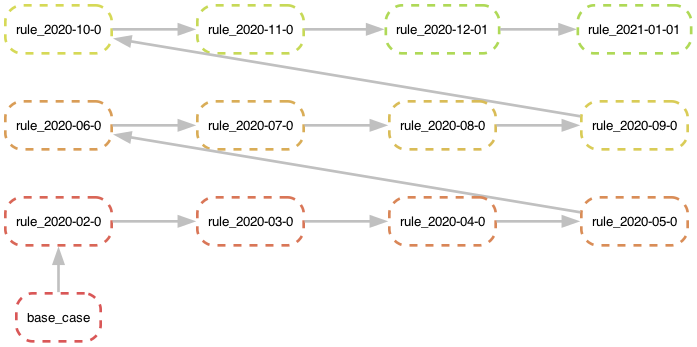
This approach is a bit more flexible, the time differences between chunks don't need to be uniform and we can have as many chunks as we want. While it is not as elegant as the recursive approach, I think it is still very readable.